Underlying modern AI is a new generation of large-scale multimodal foundation models that are pre-trained on vast amounts of unlabeled multimodal data before transferring to specialized downstream tasks. However, we lack a principled understanding of these models, learning to monolithic architectures that are often brittle and uncontrollable.
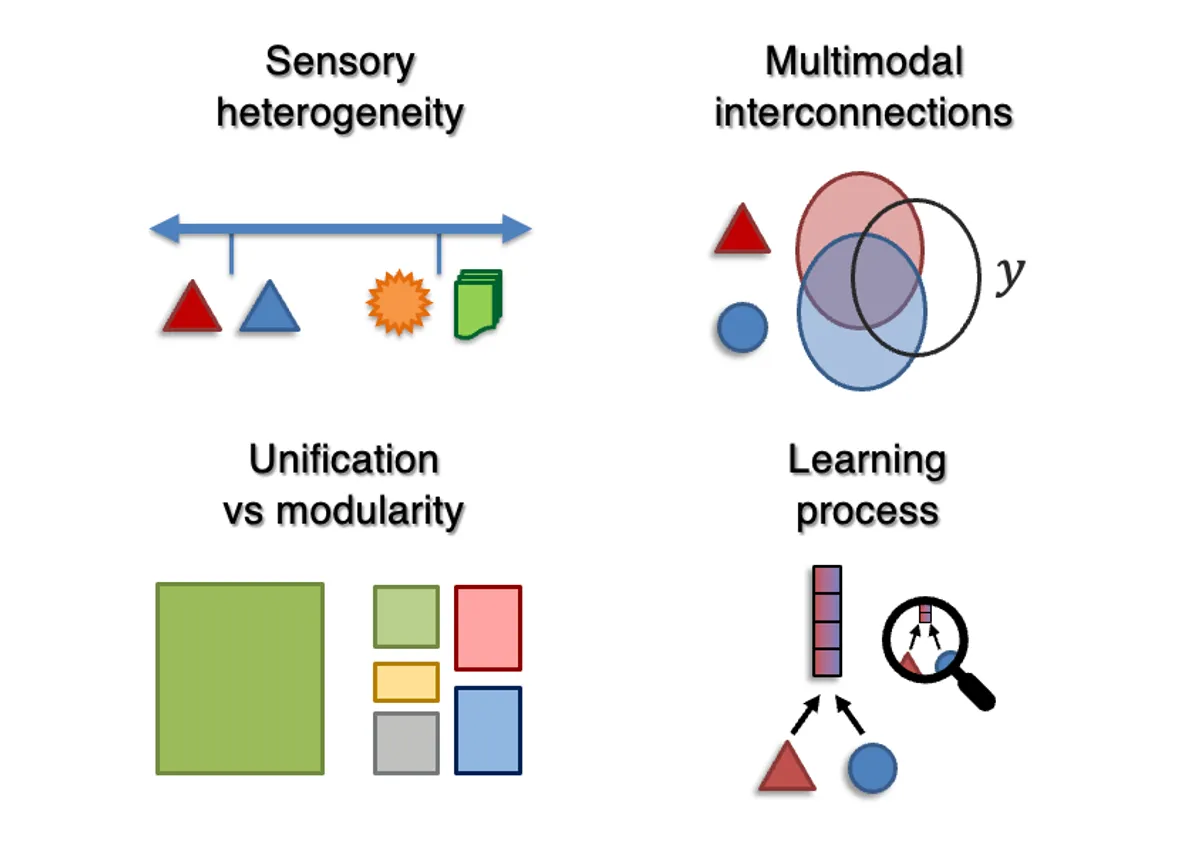
To close this gap between theory and practice, our research aims to develop a systematic understanding and learning of generalizable principles from multisensory data. Our group has a long history in developing principled approaches to quantify multimodal interactions. These interactions can be categorized into redundancy, uniqueness, and synergy: redundancy quantifies information shared between modalities, such as smiling while telling an overtly humorous joke; uniqueness quantifies the information present in only one, such as each medical sensor designed to provide new information; and synergy quantifies the emergence of new information using both, such as conveying sarcasm through disagreeing verbal and nonverbal cues. We have introduced new connections between information theory and multimodal interactions, leading to scalable estimators to quantify the interactions in large-scale multimodal datasets and those learned by multimodal models, and principled approaches to learn interactions from data. A taxonomy and pedagogy for multimodal machine learning we developed now serves as a foundational resource for the field.
Some of the most important questions we are tackling today include a principled science for quantifying data heterogeneity and multimodal interactions, developing unified modeling architectures and representations across modalities, understanding the emergence of cross-modal alignment and transfer, and quantifying how multimodal capabilities and risks change with increased data, model, and training scale to best utilize constrained resources.
Key works:
Multimodal Fusion Balancing Through Game-Theoretic Regularization, NeurIPS 2025 spotlight
Understanding the Emergence of Multimodal Representation Alignment, ICML 2025

Quantifying & Modeling Multimodal Interactions: An Information Decomposition Framework, NeurIPS 2023
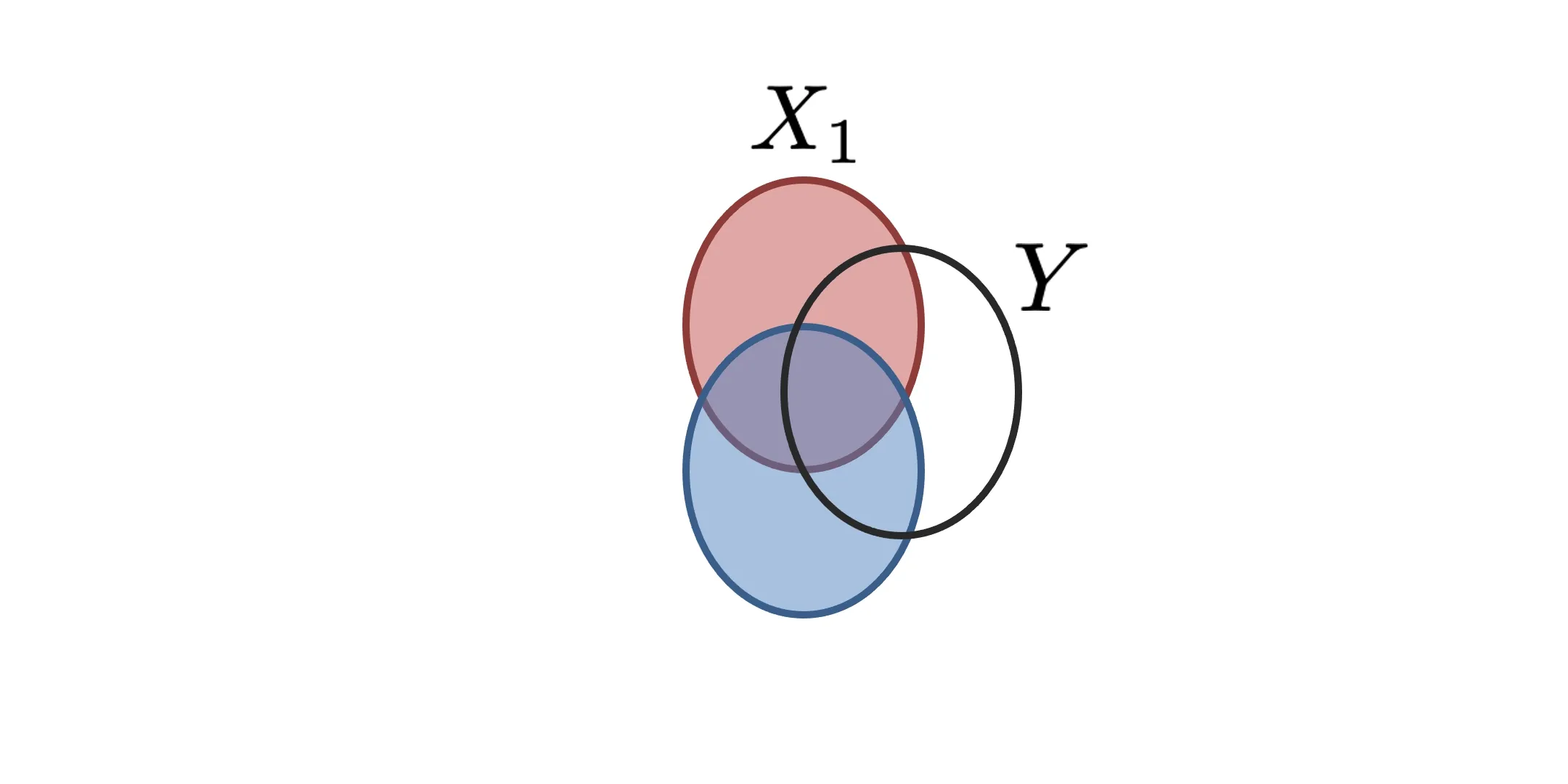
Factorized Contrastive Learning: Going Beyond Multi-view Redundancy, NeurIPS 2023